Содержание
Установка ProxMox
Тут собственно рассказывать нечего, установка очень простая.
Но на всякий случай ссылка на статью….
Первые шаги после установки Proxmox
Расширение раздела local-lvm
- Удаляем из Proxmox>Storage раздел local-lvm
- Расширяем LVM logical volume
lvextend -l +100%FREE /dev/pve/root

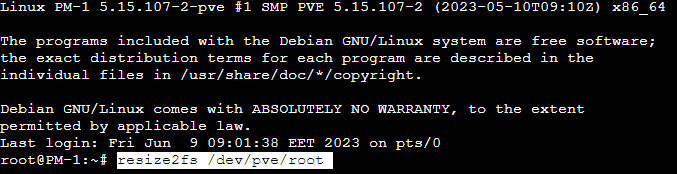
- Расширяем файловую систему, которая сидит на этом LVM logical volume:
resize2fs /dev/pve/root



Удаляем корпоративный репозиторий, добавляем фришный


Обновляем Proxmox
apt update && apt upgrade
 при необходимости - соглашаемся с закачкой.
при необходимости - соглашаемся с закачкой.
Поддержка NTFS
Установка
apt install libfuse2 ntfs-3g
Монтирование
mount -t ntfs-3g /dev/hda1 /files/windows
тут /dev/hda1 устройство, /files/windows папка куда монтируем
Размонтирование
mount -L /files/windows
Установка mdadm
apt install mdadm
Установка parted
apt install parted
Создание и подключение RAID10 из 4 дисков
Подготовка дисков
- Останавливаем RAID-массив:
mdadm -S /dev/{raid_name} - Чистим диски от инфы о предыдущих рейдах
mdadm --zero-superblock --force /dev/sd{a,b,c,d}
- создаем разделы на каждом диске
parted /dev/sdb mklabel msdos
parted /dev/sdb mkpart primary ext4 4096 931Gb
Тут /dev/sdb - диск. делаем это со всем дисками, что будут в рейде. ext4 4096 931Gb - файловая система ext4 (не поддерживаются snapshots в proxmox), 4096 - размер кластера, 931 - объем диска в гигабайтах
Создание Raid10
mdadm --create /dev/md2 --level=10 --raid-devices=4 /dev/sd[a-d]1
mdadm --create /dev/md2 --level=10 --raid-devices=4 /dev/sd[a-d]
Синхронизация рейда занимает продолжительное время. 4 диска SSD по 2ТБ синхронизировались около 2,5-3 часов. Прерывать нельзя. Проверять статус можно командой
cat /proc/mdstat
Можно изменить скорость синхронизации. По умолчанию минимальная стоит 1000 максимальная 200000.
Для изменения соответствующие команды :
echo 200000 > /proc/sys/dev/raid/speed_limit_min
echo 800000 > /proc/sys/dev/raid/speed_limit_max
По окончании синхронизации необходимо
Сохранить настройки raid и настроить автозапуск
update-initramfs -u
mdadm --detail --scan --verbose | tee -a /etc/mdadm/mdadm.conf
Добавляем строку в fstab
UUID=<UUID рейд массива, который можно найти в mdadm.conf> / ext4<или lvm> errors=remount-ro 0
- создать файловую систему на массиве
mkfs.ext4 -v -L myarray -m 0.01 -b 4096 -E stride=128,stripe-width=256 /dev/md2
- Монтирование файловой системы массива
mount /dev/md2 /mnt/raid10
здесь /mnt/raid10 - заранее созданная директория, где будет наш рейд
- делаем автоматическое монтирование RAID массива. Для этого необходимо в /etc/fstab в последней строке прописать ваш RAID массив следующим образом: /dev/md2 /raid ext4 errors=remount-ro 0 0

- Создаем physical volume:
pvcreate /dev/md2
- Если ругается, что вроде как есть ext4, соглашаемся на зачистку.
- Создаем group volume:
vgcreate pve_md2 /dev/md2
- Создаем logical volume на все свободное пространство и с опцией Thin volume:
lvcreate -n data_md2 -l 100%FREE -T pve_md2
- Может ругаться на chunk size и то что замедление возможно при обнулении. Но на SSD обнуление в принципе быстро проходит
 В proxmox теперь отображается новый раздел в PM-N/Disks/LVM-Thin . Остается только зарегистрировать хранилище.
В proxmox теперь отображается новый раздел в PM-N/Disks/LVM-Thin . Остается только зарегистрировать хранилище.
 В разделе Datacenter / Storage добавляем новое хранилище local-lvm-md2 на логическом томе data_md2 .
В разделе Datacenter / Storage добавляем новое хранилище local-lvm-md2 на логическом томе data_md2 .



Проверка состояния и лечение разных случаев RAID
Проверка состояния RAID:
cat /proc/mdstat
Пример плохого варианта:
md2 : inactive sdb[0](S) sde[3](S) sdd[2](S) sdc[1](S)
8001066336 blocks super 1.2
mdadm –detail /dev/md2
Пример плохого варианта:
/dev/md2:
Version : 1.2
Raid Level : raid0
Total Devices : 4
Persistence : Superblock is persistent
State : inactive
Working Devices : 4
Name : AgbisDedic9:2 (local to host AgbisDedic9)
UUID : 35a98a87:ea9a1235:5a903bfb:94300c96
Events : 24787283
Number Major Minor RaidDevice
- 8 64 - /dev/sde
- 8 32 - /dev/sdc
- 8 48 - /dev/sdd
- 8 16 - /dev/sdb
Еще пример:
/dev/md2:
Version : 1.2
Creation Time : Wed Jun 14 23:41:37 2023
Raid Level : raid10
Array Size : 4000532480 (3815.21 GiB 4096.55 GB)
Used Dev Size : 2000266240 (1907.60 GiB 2048.27 GB)
Raid Devices : 4
Total Devices : 3
Persistence : Superblock is persistent
Intent Bitmap : Internal
Update Time : Sat Jul 13 13:45:13 2024
State : clean, degraded
Active Devices : 3
Working Devices : 3
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : bitmap
Name : AgbisDedic9:2 (local to host AgbisDedic9)
UUID : 35a98a87:ea9a1235:5a903bfb:94300c96
Events : 24787285
Number Major Minor RaidDevice State
- 0 0 0 removed
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde
Статус одного диска:
mdadm -E /dev/sdb
Из системного журнала косвенно:
dmesg | grep md
Может быть например такое:
[ 1769.419399] md: kicking non-fresh sdc from array!
[ 1769.442811] md/raid10:md2: not enough operational mirrors.
[ 1769.443030] md: pers→run() failed …
Если из RAID выпал диск, иногда может помочь только остановка массива и пересборка, для этого:
1. mdadm –stop /dev/md2
2. Проверка состояния:
cat /proc/mdstat
3. Сборка
mdadm –assemble –force /dev/md2 /dev/sde /dev/sdc /dev/sdd /dev/sdb –verbose
Пример:
mdadm: /dev/sde is identified as a member of /dev/md2, slot 3.
mdadm: /dev/sdc is identified as a member of /dev/md2, slot 1.
mdadm: /dev/sdd is identified as a member of /dev/md2, slot 2.
mdadm: /dev/sdb is identified as a member of /dev/md2, slot 0.
mdadm: forcing event count in /dev/sdc(1) from 24755889 up to 24787283
mdadm: added /dev/sdb to /dev/md2 as 0 (possibly out of date)
mdadm: added /dev/sdd to /dev/md2 as 2
mdadm: added /dev/sde to /dev/md2 as 3
mdadm: added /dev/sdc to /dev/md2 as 1
mdadm: /dev/md2 has been started with 3 drives (out of 4).
4. Проверка состояния:
cat /proc/mdstat
mdadm - -detail /dev/md2
Если отвалился один диск
Диск в массиве можно условно сделать сбойным с помощью ключа –fail (-f)
mdadm /dev/md2 -f /dev/sda
диск должен пропасть из списка устройств
Потом заставит систему пересканировать на наличие новых устройств
echo "- - -" > /sys/class/scsi_host/host0/scan
host0 - можно менять на host1, host2 и т.д.
диск должен появится в списке устройств
После того как он появится в списке и будет корректным (PASSED), передобавим в рейд его. Система будет думать что был заменен диск
mdadm /dev/md2 –re-add /dev/sda
далее следим за синхронизацией
mdadm - -detail /dev/md2
Если переустановили систему
Нужно пересобрать raid. Для начала установить mdadm.
В консоли вводим mdadm –assemble –scan –verbose
Система должна найти все диски входящие в рейд и пересобрать его.
После чего добавляем его в наш Storage
Все диски будут на месте, но вот ВМ придется заново создавать, т.к. их конфиги хранятся в системе.
Новые ВМ должны быть без дисков и их ID совпадать с ID дисков.
После создания всех нужных ВМ в консоли PM ввести qm rescan - это добавит в каждую ВМ диски с хранилища (поиск идет по соответствию ID)
Можно добавлять диски в конфигурацию и указывать загрузочные. Система запустится.